Part 3: How we accidentally deleted our PRODUCTION environment two months after launch and how we recovered without a backup, and no one noticed.
Lessons in the trenches as a CTO. Part 3 of 3

Saturday, September 17 - 09:45 AM PST:
We breathe a sigh of collective relief. We have only lost 1 table, and it was an unused table that should have been deleted in the first place:
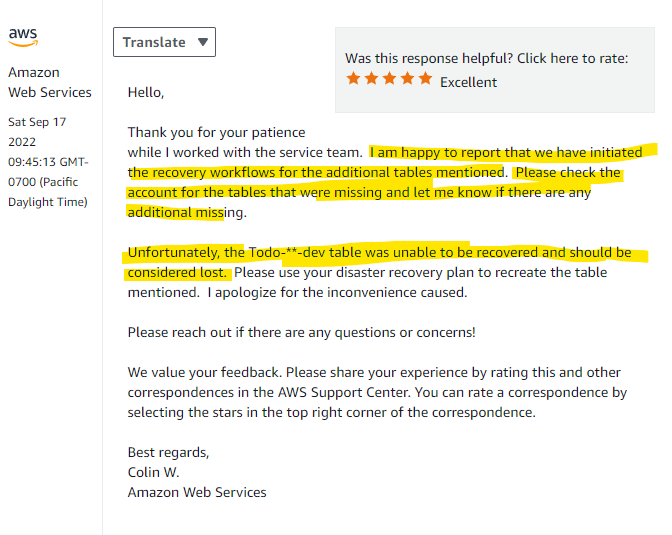
This is a huge win for the team and finally a lucky break after over 24hrs of non-stop stress and anxiety. We're able to recover the tables and have minimal data loss.
BUT...! There's still a lot of work to be done. Remember, the whole environment was deleted, not just the DB and related tables. At this point, I still have client work and the rest of the business to deal with, so I'm in and out of the war room when I can.
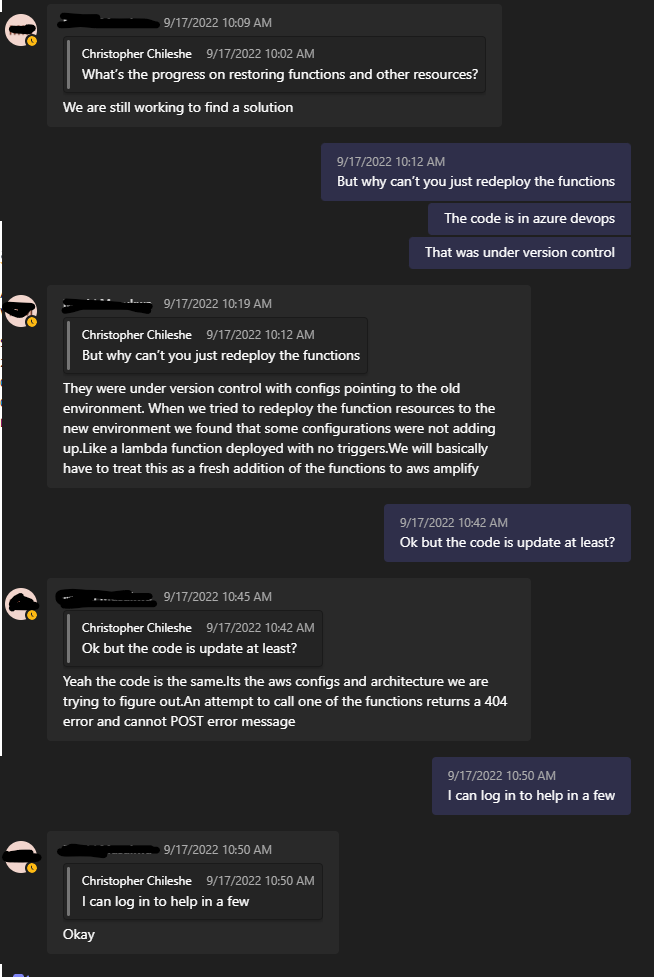
I join the call about 10mins later, and we get to work on the rest.
Saturday, September 17 - 02:07 PM PST:
It's past Midnight Central Africa Time on Sunday morning. The team is exhausted, but things are starting to function again.
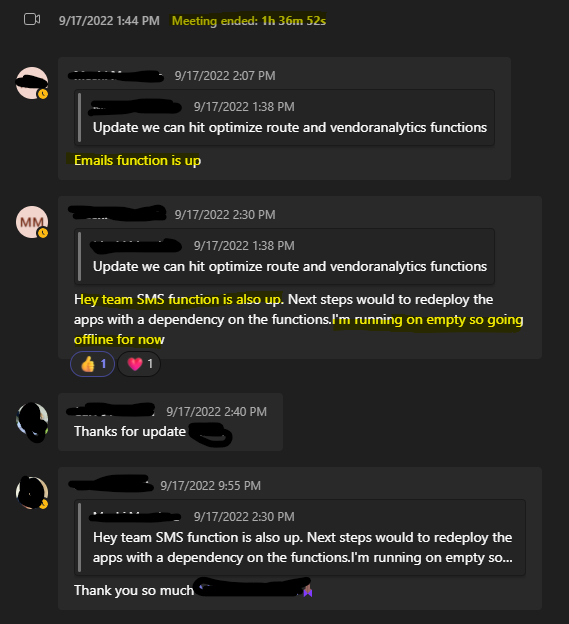
Our dev lead has been a hero through and through at this point. Keeping everyone on task while going from fire to fire. He logs off for the night.
Saturday, September 17 - 04:50 AM PST:
Hallelujah
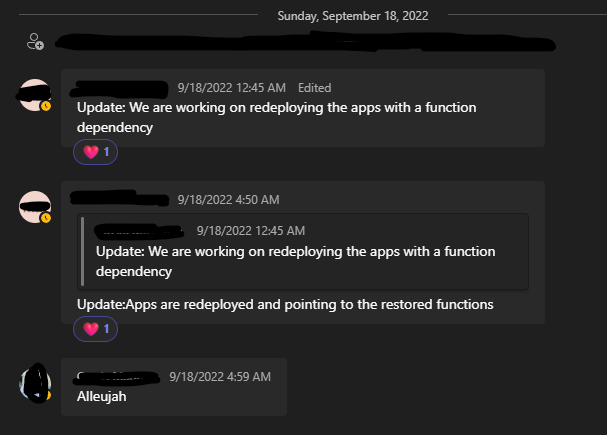
Crisis averted.
RCA (Root Cause Analysis)
Ultimately, the reason why this issue happened is because of lax permissions in production. I asked my team the five whys and we got to work resolving issues at every stage. After 45mins of discussing, we jotted down a list of priority tasks.

Here was our checklist of immediate steps to take to strengthen our restrictions in prod and mitigate the risk of this ever happening again:
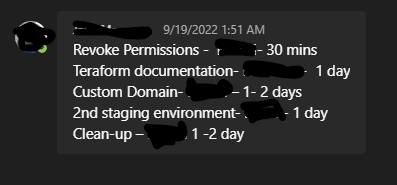
We put conservative estimates for how long it would take to complete the work.
All of our high-level fixes were done by the end of the day:
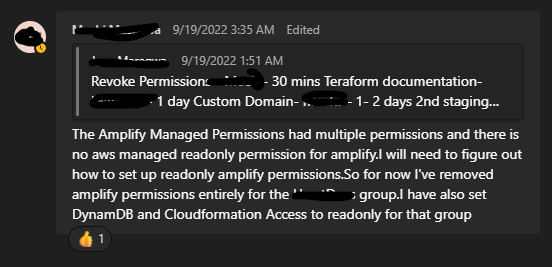
Permissions Revoked - Sunday, September 19, 3:35 AM PST:
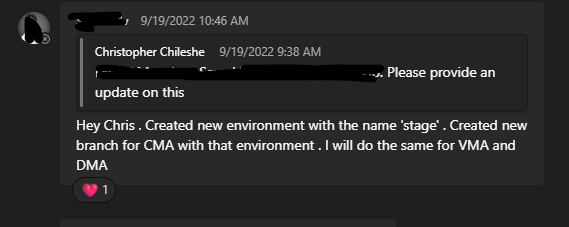
New Environments Created - Sunday, September 19, 10:46 AM PST:
Terraform Created - Sunday, September 19, 5:22 PM PST:
This also involved adding approvers to prevent roll outs without a second pair of eyes.
Custom domain took a little longer because of DNS verification, but clean-up was effectively done the same day.
Why did no one notice we were down the whole weekend?
Two main reasons why no one noticed:
Reason #1: It was early days. We had low transaction volumes, and most orders don't happen over the weekend for B2B customers.
Reason #2: We are using Amplify's Datastore feature which syncs a portion or a copy of the entire DB to the device specifically to enable offline use.
The customer apps that went unnoticed were largely because the offline feature worked as expected. The apps couldn't connect to the remote DB so they treated it as offline and kept serving local data to users, Most people were browsing the stores to get to know the app and there wasn't strong demand at this point. However, our sales team was impeded from making calls while the app was down.

No jobs were lost because of this crisis. The team pulled together and really worked hard to recover from a mistake anyone can make. It was 3 days of grueling work and sleepless nights, and we all came out of it with a stronger sense of teamwork.