How we accidentally deleted our PRODUCTION environment two months after launch and how we recovered without a backup, and no one noticed.
Lessons in the trenches as a CTO. Part 1 of 3

Now, this is a story all about how
My life got flipped-turned upside down
And I'd like to take a minute
Just sit right there
I'll tell you how we became the prince of a town called Business Continuity and Disaster Recovery. (I ashamedly spent waaaay too long trying to make it rhyme and failed... This is the best you're gonna get.)
Side note - I'll refer to Business Continuity and Disaster Recovery as BC/DR from here on out.
Thursday, September 16 - 3:20 AM PST:
After discussing a production deployment for some new features we're excited about, I log off for the night. My team is in Kenya, Zambia, and Ghana, so it's their early afternoon. Plenty of time to push to prod and test. All is well.
Friday, September 16 - 6:38 AM PST:
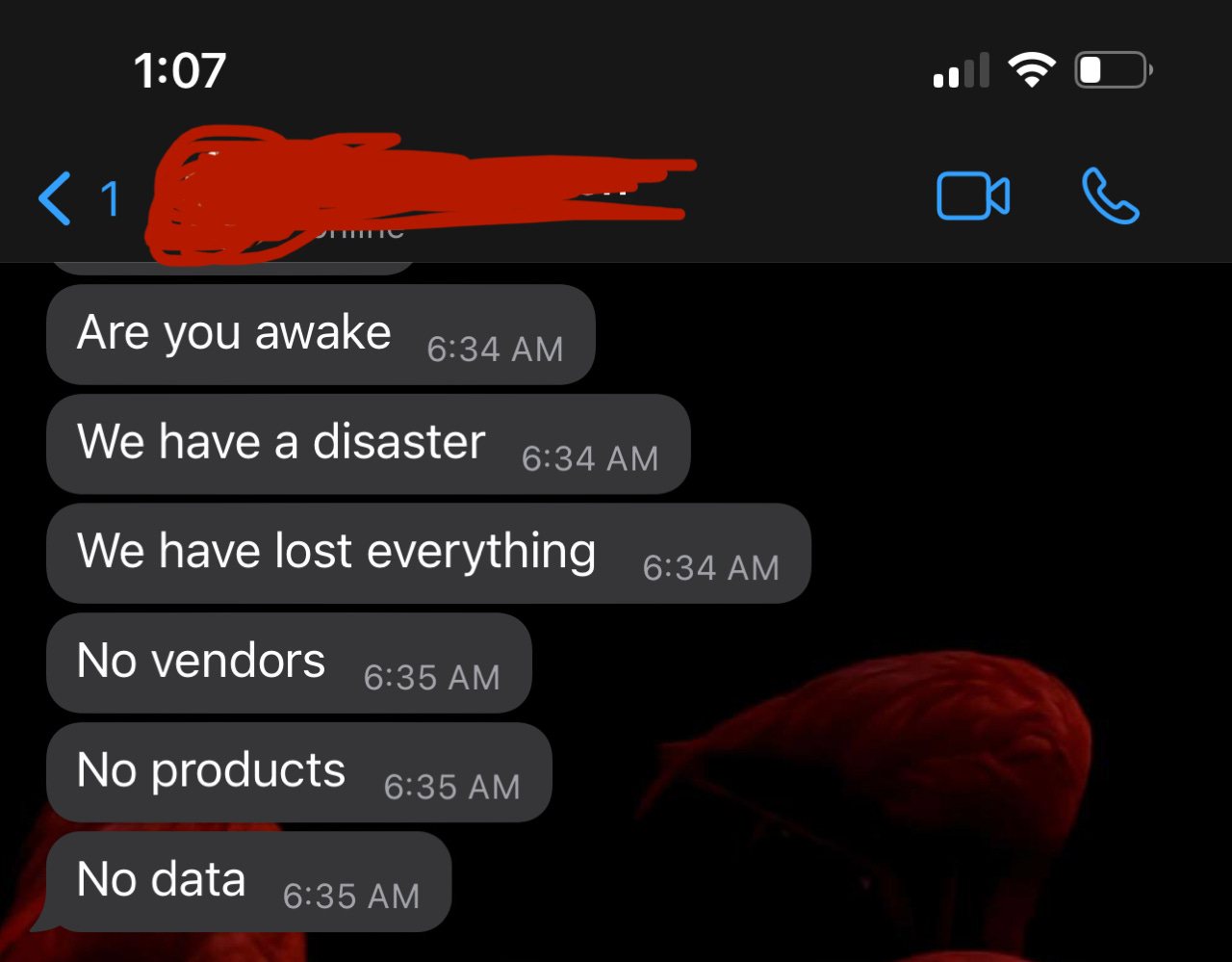
I'm on 3hrs of sleep, and we have lost everything. A surge of adrenaline rushes through my body; I jump out of bed and race down two flights of stairs to my office. I frantically and repeatedly hit the enter button on my keyboard to wake up my computer. It’s taking too long. I pull up Teams on my phone, and I can see a meeting in progress; 13 participants are on the call. It’s 4:30 PM Central Africa Time (CAT) on Friday, and the whole team and their cousins are on this call. The call connects, and I hear, "We'll need to wait until he wakes up."
My first question: "What happened?" - At this point, I'm logging into the production environment, trying to collect data and paint a clear picture of what's going on. The question almost doesn't matter in these situations because the response is almost never detailed enough to gain insights into a potential resolution, but I ask reflexively anyway.
I continue trying to log into the different systems to piece things together.
I have Gigabit internet speed...
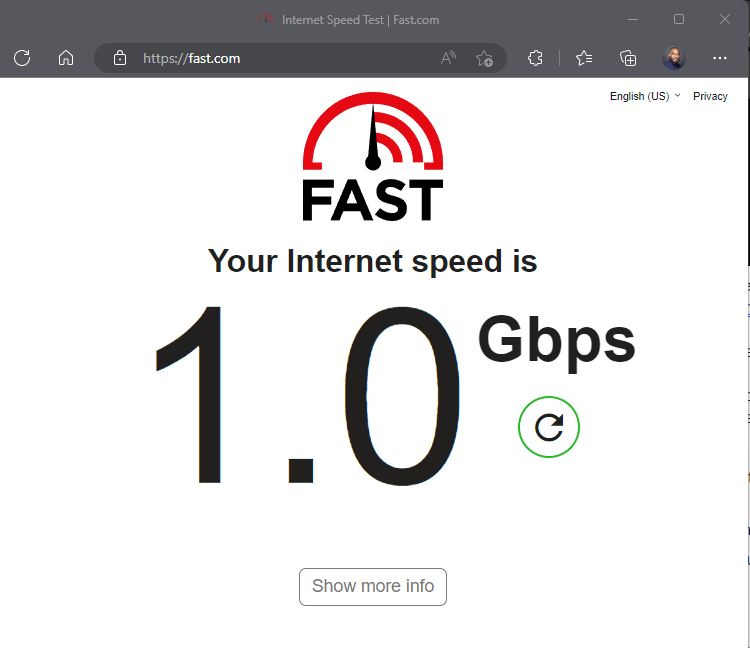
And a very capable machine (64gbs of Ram):

But today, everything is moving in slow motion. My frustration subsides a little when I finally get the push notification for 2FA to login into AWS. In hindsight, this probably only took 10 seconds end to end, but it felt like 5mins.
Curtis, our CEO: "Our production environment is gone. We've lost all of our data."
Dev Lead: "It seems our entire production instance is no longer in Amplify. We've already tried restoring from the staging environment."
Me: "OK have we tried restoring from backups?"
Dev Lead: "Yes, but we can't find the backups. Looks like we didn't have point-in-time recovery configured on"
Me: "Ok. did we contact support?"
long pregnant pause...
Dev lead: "No not yet."
Me: "Ok start there."
I fire off a series of technical questions about behavior we're seeing in different systems, listening to the variety of explanations. I learned a few things:
That our deployment got into a ROLL_BACK_FAILED state, and we tried to get past that by deleting the stack, which deleted the entire environment.
Apps from the Appstore appear to be working fine
The most recent internal build is broken, and no data shows on the app.
Internal admin tooling is also not getting any data
Our vendor web application is not getting data either.
A few mins go by as I'm collecting the facts...
Dev lead: "We don't have support. I tried logging a ticket, but we need to purchase support."
My wallet is on my desk. I pull out the company credit card, quickly navigate through the support menus and purchase an AWS Premium Support plan for $29/month. Again, everything is taking forever, but eventually, we have support purchased. I log out and log back in to refresh the page. We can see the support, and we log a ticket. Sev 1. Support will contact us in 2-4hrs
Friday September 16 - 11:13 AM PST:
It's 9:30 PM Central African Time. We finally have support on the call...
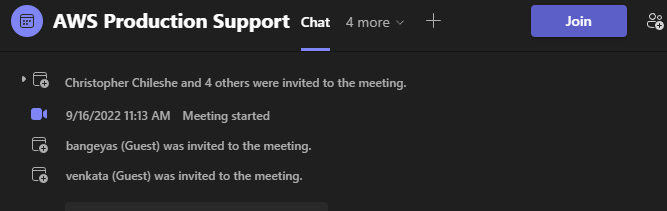
End of Part 1
5 Hindsight Lessons from Part 1:
If you don't test your BC/DR plan, you don't have a BC/DR plan.
Immediately start a war room and pull in as many people as possible to get a full picture. Anecdotes of real-time experiences from product managers, customer success, QA, and engineers helped us understand how widespread the issue was.
As soon as you believe someone has added the maximum amount of value they can, let them get back to their day job. You can see that our initial meeting started with 13 people. By the time we got on the call with production support, we were down to 4. Everyone else had contributed what was needed by them. No need to keep everyone hostage. Just ask them to be on standby in case they are needed.
Put your emotions in time out. Objectivity is important; the 'who' doesn't matter until everything is resolved.
Seems obvious now, but don't wait until you need it to purchase a support plan. Once you're in production, this shouldn't even be a debate.
Check-in tomorrow for part 2.